Competing Consumers
Camel supports the Competing Consumers from the EIP patterns book.
Camel supports the Competing Consumers from the EIP patterns directly from components that can do this. For example from SEDA, JMS, Kafka, and various AWS components.
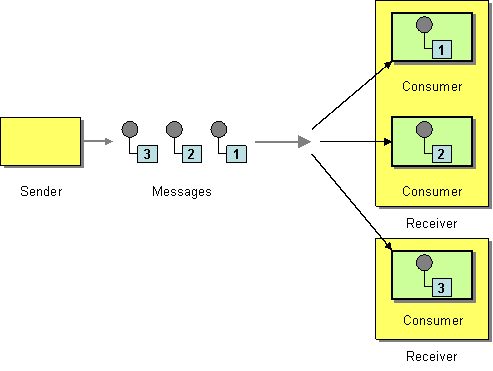
For components that do not allow concurrent consumers, then Camel allows routing from the consumer to a thread-pool which can then further process the message concurrently, which then simulates a quasi like competing consumers.
Competing Consumers with JMS
To enable Competing Consumers, you need to set the concurrentConsumers property on the JMS endpoint.
For example
-
Java
-
XML
-
YAML
from("jms:MyQueue?concurrentConsumers=5")
.to("bean:someBean");<route>
<from uri="jms:MyQueue?concurrentConsumers=5"/>
<to uri="bean:someBean"/>
</route>- from:
uri: jms:MyQueue
parameters:
concurrentConsumers: 5
steps:
- to:
uri: bean:someBeanCompeting Consumers with Thread Pool
You can simulate competing consumers by using a thread pool which then continue processing the messages concurrently. Then the single thread consumer can quickly continue and pick up new messages to process and offload them to the thread-pool (and its task queue).
Suppose we have this route where we poll a folder for new files, process the files and afterward move the files to a backup folder when complete.
-
Java
-
XML
-
YAML
from("file://inbox?move=../backup-${date:now:yyyyMMdd}")
.to("bean:calculateBean");<route>
<from uri="file://inbox?move=../backup-${date:now:yyyyMMdd}"/>
<to uri="bean:calculateBean"/>
</route>- from:
uri: "file://inbox?move=../backup-${date:now:yyyyMMdd}"
steps:
- to:
uri: bean:calculateBeanThe route is synchronous, and there is only a single consumer running at any given time. This scenario is well known, and it doesn’t affect thread safety as we only have one active thread involved at any given time.
Now imagine that the inbox folder is filled with filers quicker than we can process. So we want to speed up this process. How can we do this?
Well, we could try adding a second route with the same route path. That doesn’t work so well as we have competing consumers for the same files. That requires, however, that we use file locking, so we won’t have two consumers compete for the same file. By default, Camel supports this with its file locking option on the file component.
What if the component doesn’t support this, or it’s not possible to add a second consumer for the same endpoint? And yes, it’s a bit of a hack, and the route logic code is duplicated. And what if we need more, then we need to add a third, a fourth and so on.
What if the processing of the file itself is the bottleneck, i.e., the calculateBean is slow? So how can we process messages with this bean concurrently?
We can use the Threads EIP, so if we insert it in the route we get:
-
Java
-
XML
-
YAML
from("file://inbox?move=../backup-${date:now:yyyyMMdd}")
.threads(10)
.to("bean:calculateBean");<route>
<from uri="file://inbox?move=../backup-${date:now:yyyyMMdd}"/>
<threads poolSize="10"/>
<to uri="bean:calculateBean"/>
</route>- from:
uri: "file://inbox?move=../backup-${date:now:yyyyMMdd}"
steps:
- threads:
poolSize: 10
- to:
uri: bean:calculateBeanSo by inserting threads(10) we have instructed Camel that from this point forward in the route it should use a thread pool with up till 10 concurrent threads. So when the file consumer delivers a message to the threads, then the threads take it from there, and the file consumer can return and continue to poll the next file.
By leveraging this fact, we can still use a single file consumer to poll new files. And polling a directory to just grab the file handle is very fast. And we won’t have a problem with file locking, sorting, filtering, and whatnot. And at the same time we can leverage the fact that we can process the file messages concurrently by the calculateBean bean.
Here at the end, let’s take a closer look at what happens with the synchronous thread and the asynchronous thread. The synchronous thread hands over the exchange to the new asynchronous thread and as such, the synchronous thread completes. The asynchronous thread is then routing and processing the message. And when this thread finishes, it will take care of the file completion strategy to move the file into the backup folder. This is an important note that the on completion is done by the asynchronous thread.
This ensures the file is not moved before the file is processed successfully. Suppose the calculateBean bean could not process one of the files. If it was the asynchronous thread that should do the on completion strategy, then the file would have been moved to early into the backup folder. By handing over this to the asynchronous thread, we do it after we have processed the message completely